- $19.00 on Teachable
Course overview
How programming languages work under the hood? What’s the difference between compiler and interpreter? What is a virtual machine, and JIT-compiler? And what about the difference between functional and imperative programming?
There are so many questions when it comes to implementing a programming language!
![]()
The problem with “compiler classes” in school is such classes are usually presented as some “hardcore rocket science” which is only for advanced engineers.
Moreover, classic compiler books start from the least significant topic, such as Lexical analysis, going straight down to the theoretical aspects of formal grammars. And by the time of implementing the first Tokenizer module, students simply lose an interest to the topic, not having a chance to actually start implementing a programing language itself. And all this is spread to a whole semester of messing with tokenizers and BNF grammars, without understanding an actual semantics of programming languages.
I believe we should be able to build and understand a full programming language semantics, end-to-end, in 4-6 hours — with a content going straight to the point, showed in live coding sessions as pair-programming and described in a comprehensible way.
In the Building a Virtual Machine class we focus specifically on runtime semantics, and build a stack-based VM for a programming language very similar to JavaScript or Python. Working closely with the bytecode level you will understand how lower-level interpretation works in production VMs today.
Implementing a programing language would also make your practical level in other programming languages more professional.
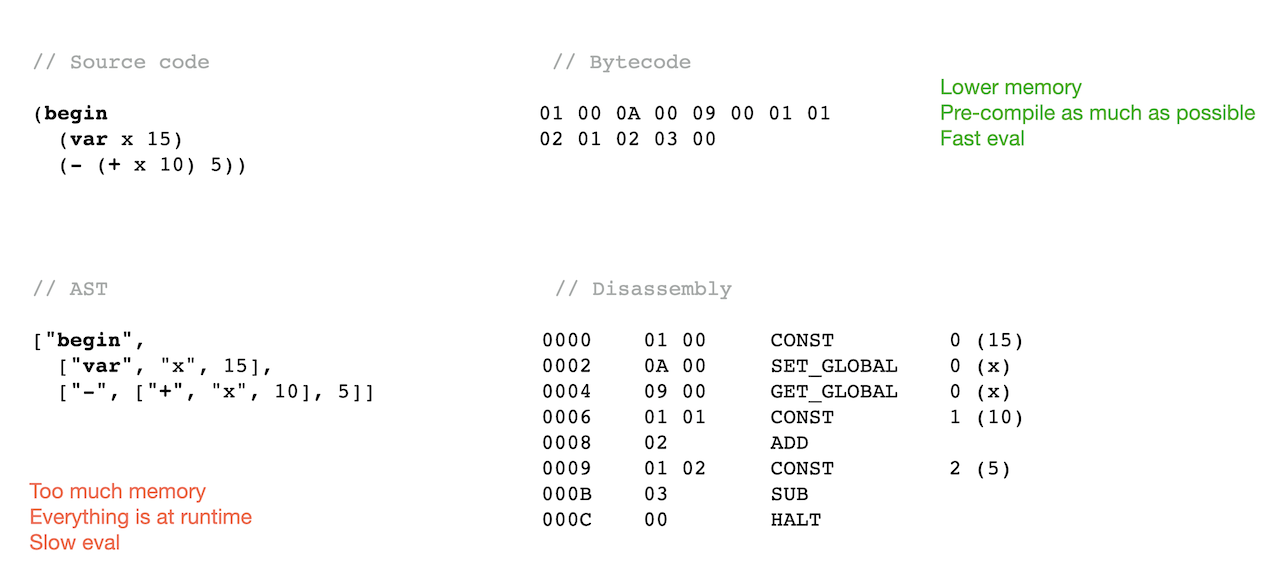
How to?
You can watch preview lectures, and also enroll to the full course, covering implementation of an interpreter from scratch, in animated and live-annotated format. See details below what is in the course.
Promo coupons:
|
Prerequisites
There are two prerequisites for this class.
The Building a Virtual Machine course is a natural extension for the previous class — Building an Interpreter from scratch (aka Essentials of Interpretation), where we build also a full programming language, but at a higher, AST-level. Unless you already have understanding of how programming languages work at this level, i.e. what eval, a closure, a scope chain, environments, and other constructs are — you have to take the interpreters class as a prerequisite.
Also, going to lower (bytecode) level where production VMs live, we need to have basic C++ experience. This class however is not about C++, so we use just very basic (and transferrable) to other languages constructs.
Watch the introduction video for the details.
Who this class is for?
This class is for any curious engineer, who would like to gain skills of building complex systems (and building a programming language is an advanced engineering task!), and obtain a transferable knowledge for building such systems.
If you are interested specifically in compilers, bytecode interpreters, virtual machines, and source code transformation, then this class is also for you.
What is used for implementation?
Since lower-level VMs are about performance, they are usually implemented in a low-level language such as C or C++. This is exactly what we use as well, however mainly basic features from C++, not distracting to C++ specifics. The code should be easily convertible and portable to any other language, e.g. to Rust or even higher-level languages such as JavaScript — leveraging typed arrays to mimic memory concept. Using C++ also makes it easier implementing further JIT-compiler.
Note: we want our students to actually follow, understand and implement every detail of the VM themselves, instead of just copy-pasting from final solution. Even though the full source code for the language is presented in the video lectures, the code repository for the project contains /* Implement here */ assignments, which students have to solve.
What’s specific in this class?
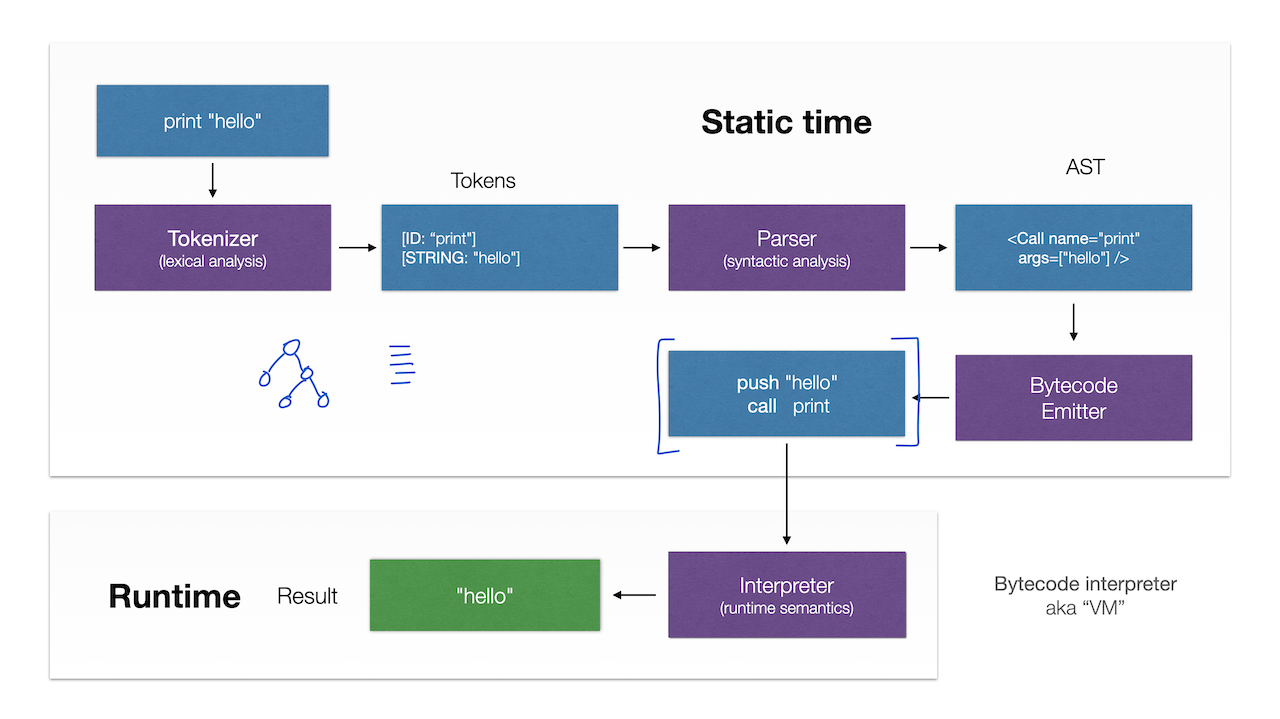
The main features of these lectures are:
- Concise and straight to the point. Each lecture is self-sufficient, concise, and describes information directly related to the topic, not distracting on unrelated materials or talks.
- Animated presentation combined with live-editing notes. This makes understanding of the topics easier, and shows how the object structures are connected. Static slides simply don’t work for a complex content.
- Live coding session end-to-end with assignments. The full source code, starting from scratch, and up to the very end is presented in the video lectures
What is in the course?
The course is divided into five parts, in total of 29 lectures, and many sub-topics in each lecture. Below is the table of contents and curriculum.
Part 1: VM basic operations
In this part we describe compilation and interpretation pipeline, starting building our language. Topics of Stack and Register VMs, heap-allocated objects and compilation of the bytecode are discussed.
- Lecture 1: Introduction to Virtual Machines
- Course overview and agenda
- Parsing pipeline
- Tokenizer module (Lexical analysis)
- Parser module (Syntactic analysis)
- Abstract Syntax Tree (AST)
- Interpreters vs. Compilers
- AST interpreters
- Bytecode interpreters
- Eva programming language
- S-expression
- Instruction pointer
- Eval loop
- Halt instruction
- Lecture 2: Stack-based vs. Register-based VMs
- Stack-based VM
- Stack pointer
- Constant pool
- Java bytecode example
- Python bytecode example
- Compiler explorer tool
- Register-based VM
- Accumulator register
- Lecture 3: Logger implementation
- Program exit macro
- Streaming error messages
- Logging values
- Lecture 4: Numbers | Introduction to Stack
- CONST instruction
- Constant pool
- Operands stack
- Push and pop
- Eva value encoding
- Tagged unions
- Stack overflow
- Simple numbers
- Value accessors
- Lecture 5: Math binary operations
- Binary instructions
- Math operators
- Generic binary macro
- Introduction to LLDB
- Step debugging
- Stack introspection
- Complex operation
- FILO/LIFO stack specifics
- Lecture 6: Strings | Introduction to Heap and Objects
- Generic Object type
- Heap-allocated values
- String object type
- String concatenation
- Memory leaks and Garbage Collection
- Lecture 7: Syntax | Parser implementation
- Parser generators: Syntax tool
- BNF grammars (Backus-Naur Form)
- S-Expression grammar
- AST node types: Atoms, Lists
- LLDB introspection
- Lecture 8: Compiler | Bytecode
- Introduction to Compiler
- Code objects
- AST traversal
- Recursive code generation
- Compiling numbers and strings
- Lecture 9: Complex expressions
- Lists compilation
- Value representation
- Nested expressions
- Compiling math operations









Part 2: Control flow and variables
In this part we implement control flow structures such as if expressions and while loops, talk about Global object and global variables, nested blocks and local variables, and also implement a disassembler.
- Lecture 10: Comparison | Booleans
- Boolean values
- Comparison operators
- Branch instruction
- Lecture 11: Control flow | Branch instruction
- Control flow
- If-else expression
- Branch instruction
- Conditional jumps
- Unconditional jumps
- Bytecode patching
- Lecture 12: Disassembler
- Introduction to Disassembler
- Bytecode offsets
- Decompiling instructions
- Opcode string representation
- Instruction operands
- Lecture 13: Global variables
- Variable declaration
- Value access
- Global object and storage
- Variable update
- Lecture 14: Blocks | Local variables
- Blocks: groups of expressions
- Pop operation
- Local scope and local variables
- Scope enter and Scope exit
- Base pointer (aka Frame pointer)
- Lecture 15: Control flow | While-loops
- Control flow
- While loops
- For loops
- Jump instructions
- Bytecode patching






Part 3.1: Functions and Call stack
In this part we start talking and implementing function abstraction and function calls. We describe concept of the Call stack, native and user-defined functions, and IILEs (Immediately-invoked lambda expressions).
- Lecture 16: Native functions
- Native function objects
- Function calls
- Function arity
- Arguments on the stack
- Callee cleanup
- Stack dump
- Lecture 17: User-defined functions
- Function objects
- Code objects
- Custom bytecode
- Function parameters
- Scope exit
- Return operator
- Lecture 18: Call stack | Return address
- Function calls
- Jumping to function code
- Call stack
- Stack frame
- Return address
- Base pointer
- Return operator
- Lecture 19: Lambda functions
- Anonymous functions
- Immediately-invoked Lambda Expressions (IILE)
- Syntactic sugar
- Lecture 20: Bytecode optimizations
- Optimizing compiler
- Bytecode restructuring
- Automatic POP for globals
- Automatic initialization of locals
- Relative jumps
- Pre-calculation of simple values





Part 3.2: Closures implementation
In this part we focus on closures implementation, talking about scope and escape analysis, capturing free variables, and adding runtime support for closures.
- Lecture 21: Closures | Scope analysis
- Introduction to closures
- Global, Locals and Cells
- Stack and Heap allocation
- Scope structure
- Escape analysis
- Cell promotion
- Lecture 22: Closures | Compilation
- Globals, Locals, and Cells
- Compiler support for cells
- Scope info
- Scope stack
- Lecture 23: Closures | Runtime
- Environments
- Cell objects
- Closure objects
- Free and Own cells
- Capturing free variables



Part 4: Garbage Collection
This part is devoted to the automatic memory management known as Garbage collection. We discuss a tracing heap and implement Mark-Sweep garbage collector.
- Lecture 24: Tracing heap | Object header
- Introduction to Garbage collectors
- Managed vs. Unmanaged languages
- Tracing heap
- Allocation | Deallocation
- Object header
- Memory stats
- GC roots
- Constant roots
- Lecture 25: Mark-Sweep GC
- Mark-Sweep GC algorithm
- Abstract code and implementation
- GC roots: stack, constants, globals
- GC threshold
- Tracing heap
- Free list
- Garbage reclaim


Part 5: Object-oriented programming
In the final part we add support for Object-oriented programming, implementing classes and instances. In addition we build the final VM executable.
- Lecture 26: Class objects | Methods storage
- Object-oriented programming
- Class objects
- Inner vs. Global classes
- Static vs. Dynamic dispatch
- Environments
- Methods resolution
- Lecture 27: Instance objects | Property access
- Object-oriented programming
- Instance objects
- Inheritance
- Self object
- Constructor function
- Property access
- Bytecode patching
- Lecture 28: Super classes | Inheritance
- Child classes
- Super classes
- Inheritance chains
- Lecture 29: Final VM executable
- Eva VM executable
- Evaluating expressions
- Executing files
- Next steps
- Assembly




I hope you’ll enjoy the class and will be glad to discuss any questions and suggestion in comments.
Hi Dmitry,
I am really enjoying “Building a virtual machine”. But your description talks about project repository where “implement here” placeholders would be there. But I see no reference to location of the repo. Where does the repo live?
Hi Shivani, thanks for the feedback and the interested, glad you like the course. The repo should be available in the description of lectures on Udemy/Techable. Let me know if you have any issues with access there.
Hi Dmitry
I bought the “Building a Virtual Machine” course. Can I find somewhere the complete solution/code because on Github I only found the skeleton (https://github.com/DmitrySoshnikov/eva-vm-source).
This would help me to get a better overview over the components and understand how the things are connected together because in the videos you only see one snippet/piece of code at a time.
Best regards
David
Hi David – yes, as mentioned in the course description, we want our students to actually follow the lectures and build the VM from scratch, instead of copy-pasting from the final solutions. That’s why all the code repositories contain the main skeleton with the “TODO” assignments. This is the philosophy used in all other courses as well. The video lectures should contain the whole source code, but please let me know if any parts are missing.