This is the 6th lecture from the Garbage Collection Algorithms class, devoted to the automatic memory management.
Before discussing algorithms of collecting the garbage, we need to see how these objects (which eventually become a garbage) are allocated on the heap. In today’s lecture we consider mechanisms of memory allocation.
Note: see also related lectures on Writing a Pool Allocator, and Writing a Mark-Sweep Garbage Collector.
Audience: advanced engineers
This is a lab session, where we’re going to implement a memory allocator, similar to the one used in malloc function. In addition, we discuss the theory behind the allocators, talking about sequential (aka “bump allocators”), and the free-list allocators.
Prerequisites for this lab session are the:
- Lecture 3: Object header
- Lecture 4: Virtual Memory and Memory Layout
- Lecture 5: Mutator, Collector, Allocator
Video lecture
Before going to the lab session, you can address corresponding video lecture on Memory Allocators, which is available at:
Lecture 6/16: Allocators: Free-list vs. Sequential
Mutator, Allocator, Collector
From the previous lectures we know that a garbage-collected program is manipulated by the three main modules known as Mutator, Allocator, and Collector.
Mutator is our user-program, where we create objects for own purposes. All the other modules should respect the Mutator’s view on the object graph. For example, under no circumstances a Collector can reclaim an alive object.
Mutator however doesn’t allocate objects by itself. Instead it delegates this generic task to the Allocator module — and this is exactly the topic of our discussion today.
Here is an overview picture of a GC’ed program:
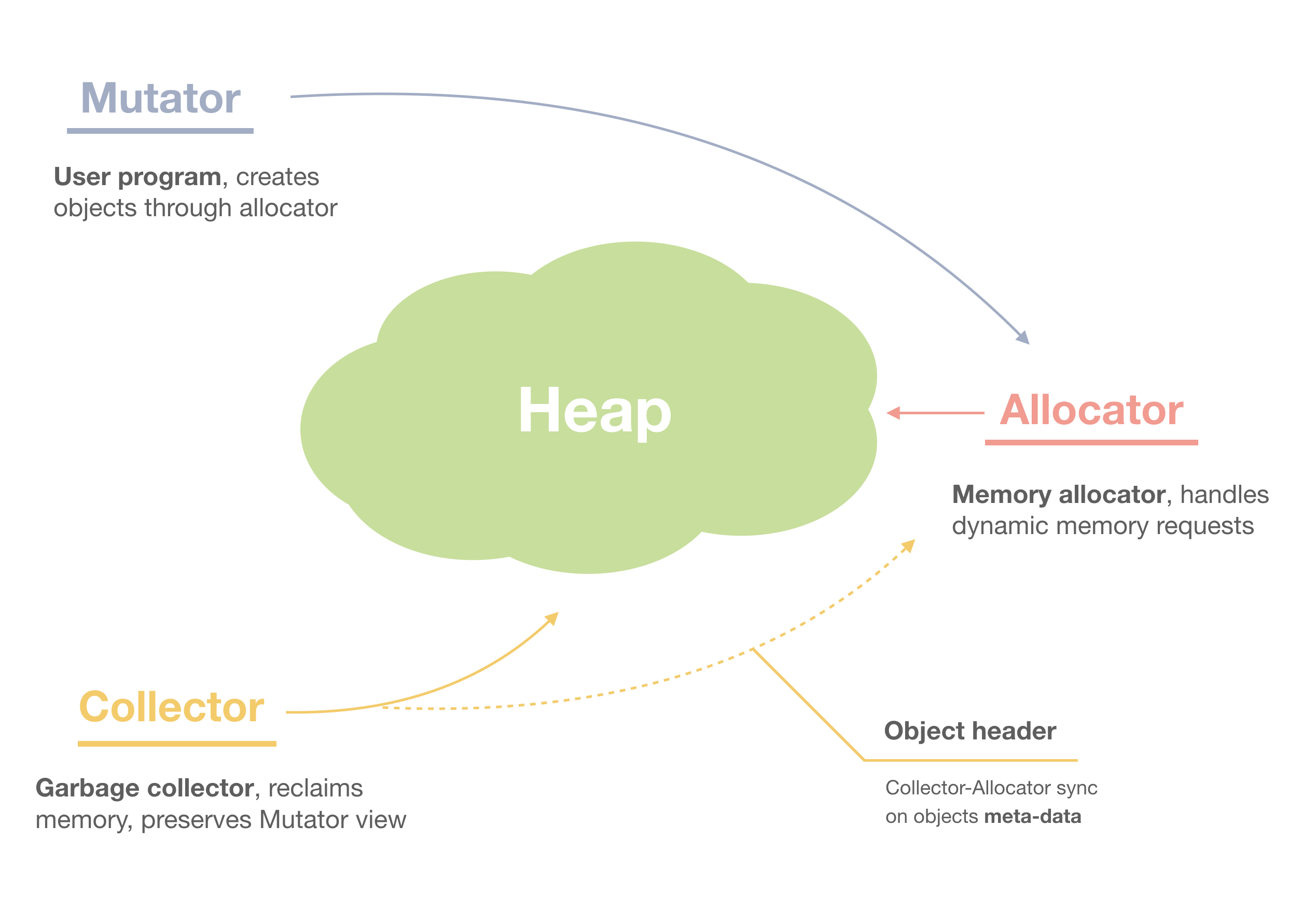
Figure 1. Mutator, Allocator, Collector
Let’s dive into the details of implementing a memory allocator.
Memory block
Usually in higher-level programming languages we deal with objects, which have a structure, fields, methods, etc:
const rect = new Rectangle({width: 10, height: 20});
From a memory allocator perspective though, which works at lower-level, an object is represented as just a memory block. All is known is that this block is of certain size, and its contents, being opaque, treated as raw sequence of bytes. At runtime this memory block can be casted to a needed type, and its logical layout may differ based on this casting.
Recall from the lecture devoted to the Object header, that memory allocation is always accompanied by the memory alignment, and the object header. The header stores meta-information related to each object, and which servers the allocator’s, and collector’s purposes.
Our memory block will combine the object header, and the actual payload pointer, which points to the first word of the user data. This pointer is returned to the user on allocation request:
/**
* Machine word size. Depending on the architecture,
* can be 4 or 8 bytes.
*/
using word_t = intptr_t;
/**
* Allocated block of memory. Contains the object header structure,
* and the actual payload pointer.
*/
struct Block {
// -------------------------------------
// 1. Object header
/**
* Block size.
*/
size_t size;
/**
* Whether this block is currently used.
*/
bool used;
/**
* Next block in the list.
*/
Block *next;
// -------------------------------------
// 2. User data
/**
* Payload pointer.
*/
word_t data[1];
};
As you can see, the header tracks the size of an object, and whether this block is currently allocated — the used flag. On allocation it’s set to true, and on the free operation it’s reset back to false, so can be reused in the future requests. In addition, the next field points to the next block in the linked list of all available blocks.
The data field points to the first word of the returning to a user value.
Here is a picture of how the blocks look in memory:
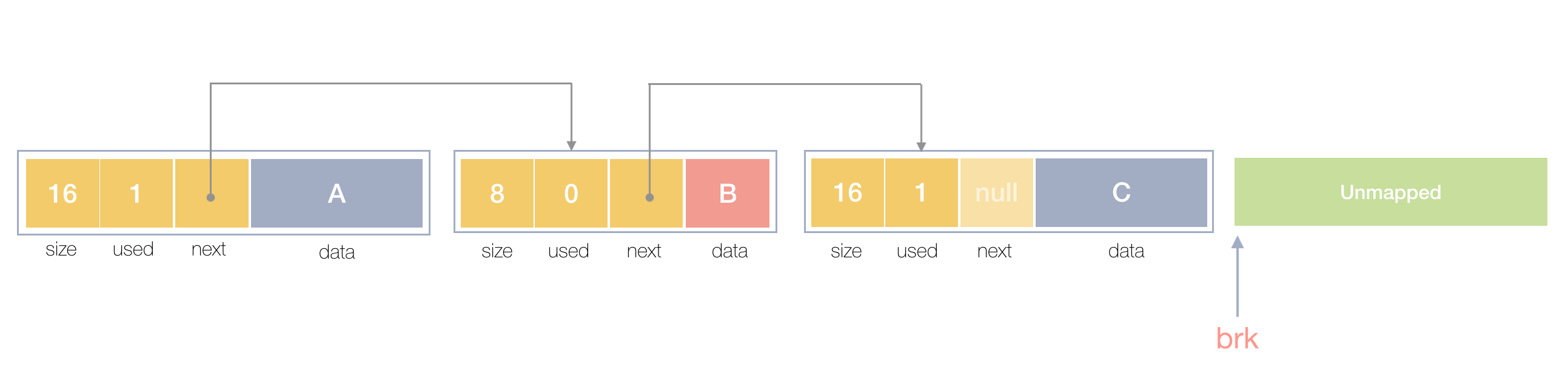
Figure 2. Memory blocks
The objects A, and C are in use, and the block B is currently not used.
Since this is a linked list, we’ll be tracking the start and the end (the top) of the heap:
/** * Heap start. Initialized on first allocation. */ static Block *heapStart = nullptr; /** * Current top. Updated on each allocation. */ static auto top = heapStart;
Shall I use C++ for implementation?
ArrayBuffer, or similarly bytearray in Python, Rust, etc.Allocator interface
As mentioned, when allocating a memory, we don’t make any commitment about the logical layout of the objects, and instead work with the size of the block.
Mimicking the malloc function, we have the following interface (except we’re using typed word_t* instead of void* for the return type):
/**
* Allocates a block of memory of (at least) `size` bytes.
*/
word_t *alloc(size_t size) {
...
}
Why is it “at least” of size bytes? Because of the padding or alignment, which we should discuss next.
Memory alignment
For faster access, a memory block should be aligned, and usually by the size of the machine word.
Here is the picture how an aligned block with an object header looks like:
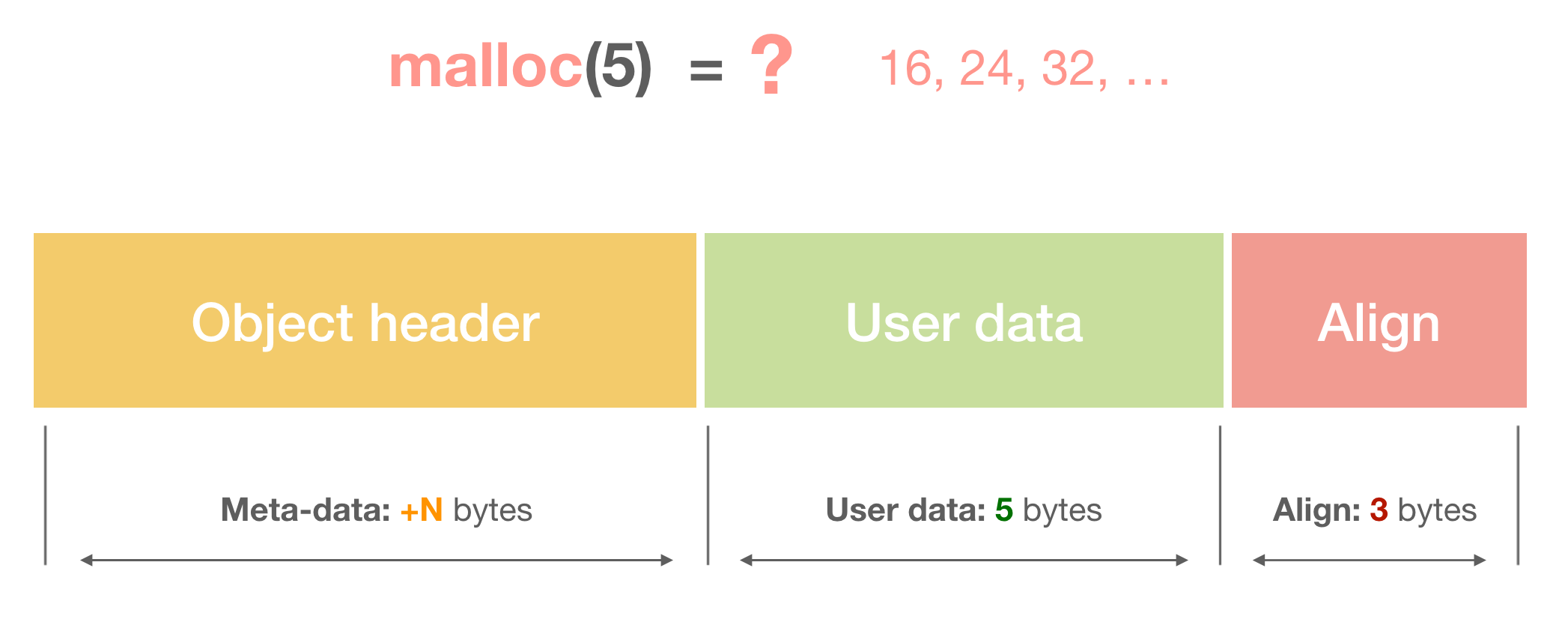
Figure 3. Aligned block with a header
Let’s define the aligning function, which looks a bit cryptic, but does the job well:
/**
* Aligns the size by the machine word.
*/
inline size_t align(size_t n) {
return (n + sizeof(word_t) - 1) & ~(sizeof(word_t) - 1);
}
What this means, is if a user requests to allocate, say, 6 bytes, we actually allocate 8 bytes. Allocating 4 bytes can result either to 4 bytes — on 32-bit architecture, or to 8 bytes — on x64 machine.
Let’s do some tests:
// Assuming x64 architecture: align(3); // 8 align(8); // 8 align(12); // 16 align(16); // 16 ... // Assuming 32-bit architecture: align(3); // 4 align(8); // 8 align(12); // 12 align(16); // 16 ...
So this is the first step we’re going to do on allocation request:
word_t *alloc(size_t size) {
size = align(size);
...
}
OK, so far so good. Now we need to recall the topics of virtual memory and memory mapping, and see what allocation actually means from the operating system perspective.
Memory mapping
From the Lecture 4 about virtual memory of a process, we remember that “to allocate a memory” from OS, means “to map more memory” for this process.
Let’s recall the memory layout again, and see where the heap region resides.
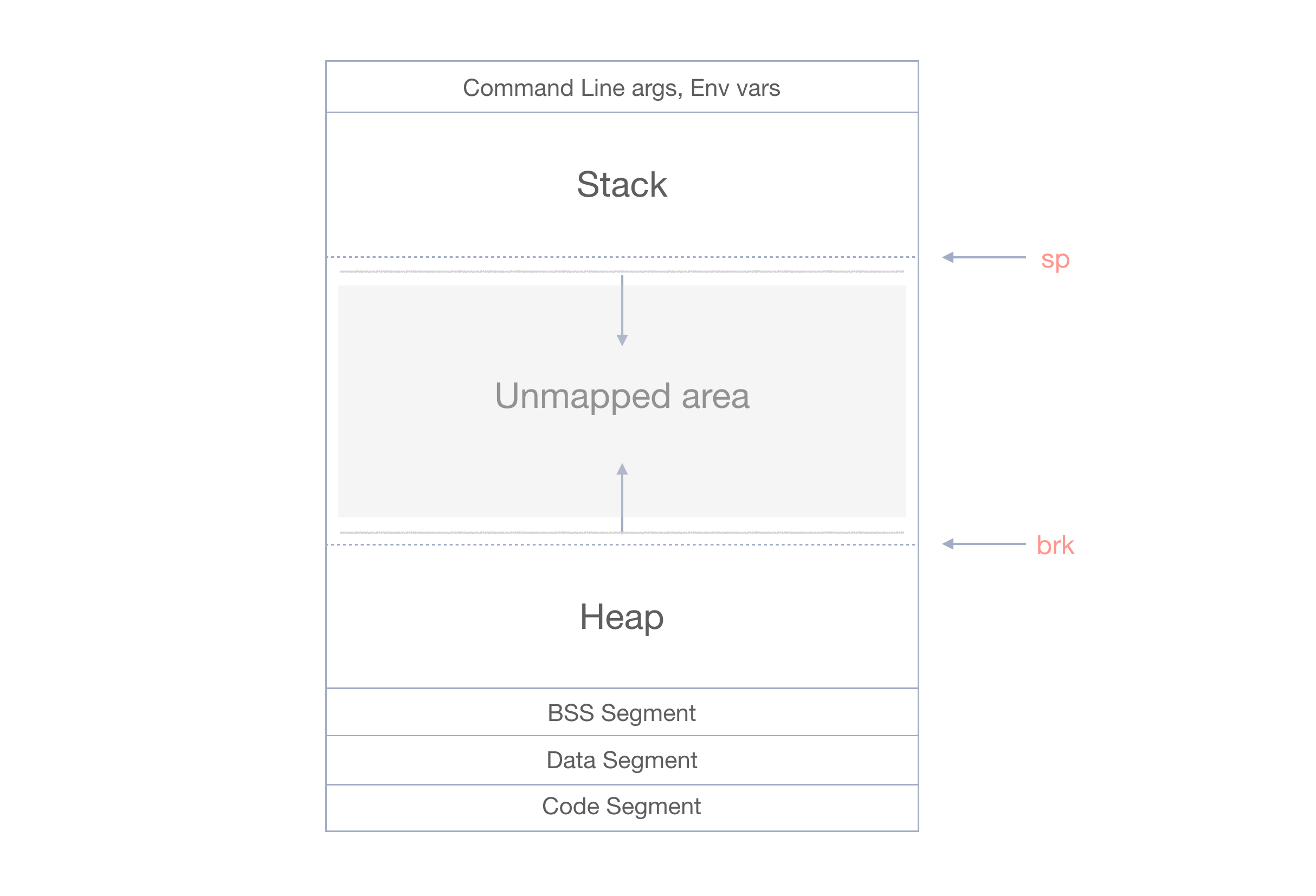
Figure 4. Memory Layout
As we can see, the heap grows upwards, towards the higher addresses. And the area in between the stack and the heap is the unmapped area. Mapping is controlled by the position of the program break (brk) pointer.
There are several system calls for memory mapping: brk, sbrk, and mmap. Production allocators usually use combination of those, however here for simplicity we’ll be using only the sbrk call.
Having current top of the heap, the sbrk function increases (“bumps”) the value of the program break on the passed amount of bytes.
Here is the procedure for requesting memory from OS:
#include <unistd.h> // for sbrk
...
/**
* Returns total allocation size, reserving in addition the space for
* the Block structure (object header + first data word).
*
* Since the `word_t data[1]` already allocates one word inside the Block
* structure, we decrease it from the size request: if a user allocates
* only one word, it's fully in the Block struct.
*/
inline size_t allocSize(size_t size) {
return size + sizeof(Block) - sizeof(std::declval<Block>().data);
}
/**
* Requests (maps) memory from OS.
*/
Block *requestFromOS(size_t size) {
// Current heap break.
auto block = (Block *)sbrk(0); // (1)
// OOM.
if (sbrk(allocSize(size)) == (void *)-1) { // (2)
return nullptr;
}
return block;
}
By calling the sbrk(0) in (1), we obtain the pointer to the current heap break — this is the beginning position of the newly allocated block.
Next in (2) we call sbrk again, but this time already passing the amount of bytes on which we should increase the break position. If this call results to (void *)-1, we signal about OOM (out of memory), returning the nullptr. Otherwise we return the obtained in (1) address of the allocated block.
To reiterate the comment on the allocSize function: in addition to the actual requested size, we should add the size of the Block structure which stores the object header. However, since the first word of the user data is already automatically reserved in the data field of the Block, we decrease it.
We’ll be calling requestFromOS only when no free blocks available in our linked list of blocks. Otherwise, we’ll be reusing a free block.
sbrk is deprecated and is currently emulated via mmap, using a pre-allocated arena of memory under the hood.
To use sbrk with clang on Mac OS without warnings, add the:
#pragma clang diagnostic push #pragma clang diagnostic ignored "-Wdeprecated-declarations"
As one of the assignments below you’ll be suggested to implement a custom version of sbrk, and also on top of the mmap call.
OK, now we can request the memory from OS:
/**
* Allocates a block of memory of (at least) `size` bytes.
*/
word_t *alloc(size_t size) {
size = align(size);
auto block = requestFromOS(size);
block->size = size;
block->used = true;
// Init heap.
if (heapStart == nullptr) {
heapStart = block;
}
// Chain the blocks.
if (top != nullptr) {
top->next = block;
}
top = block;
// User payload:
return block->data;
}
Let’s add a helper function to obtain a header from a user pointer:
/**
* Returns the object header.
*/
Block *getHeader(word_t *data) {
return (Block *)((char *)data + sizeof(std::declval<Block>().data) -
sizeof(Block));
}
And experiment with the allocation:
#include <assert.h>
...
int main(int argc, char const *argv[]) {
// --------------------------------------
// Test case 1: Alignment
//
// A request for 3 bytes is aligned to 8.
//
auto p1 = alloc(3); // (1)
auto p1b = getHeader(p1);
assert(p1b->size == sizeof(word_t));
// --------------------------------------
// Test case 2: Exact amount of aligned bytes
//
auto p2 = alloc(8); // (2)
auto p2b = getHeader(p2);
assert(p2b->size == 8);
...
puts("\nAll assertions passed!\n");
}
In (1) the allocation size is aligned to the size of the word, i.e. 8 on x64. In (2) it’s already aligned, so we get 8 too.
You can compile it using any C++ complier, for example clang:
# Compile: clang++ alloc.cpp -o alloc # Execute: ./alloc
As a result of this execution you should see the:
All assertions passed!
OK, looks good. Yet however we have one “slight” (read: big) problem in this naïve allocator — it’s just continuously bumping the break pointer, requesting more, and more memory from OS. At some point we’ll just run out of memory, and won’t be able to satisfy an allocation request. What we need here is an ability to reuse previously freed blocks.
Note: the allocator from above is known as Sequential allocator (aka the “Bump”-allocator). Yes, it’s that trivial, and just constantly bumping the allocation pointer until it reaches the “end of the heap”, at which point a GC is called, which reclaims the allocation area, relocating the objects around. Below we implement a Free-list allocator, which can reuse the blocks right away.
We’ll first look at objects freeing, and then will improve the allocator by adding the reuse algorithm.
Freeing the objects
The free procedure is quite simple and just sets the used flag to false:
/**
* Frees a previously allocated block.
*/
void free(word_t *data) {
auto block = getHeader(data);
block->used = false;
}
The free function receives an actual user pointer from which it obtains the corresponding Block, and updates the used flag.
The corresponding test:
... // -------------------------------------- // Test case 3: Free the object // free(p2); assert(p2b->used == false);
Plain simple. OK, now let’s finally implement the reuse functionality, so we don’t exhaust quickly all the available OS memory.
Blocks reuse
Our free function doesn’t actually return (unmap) the memory back to OS, it just sets the used flag to false. This means we can (read: should!) reuse the free blocks in future allocations.
Our alloc function is updated as follows:
/**
* Allocates a block of memory of (at least) `size` bytes.
*/
word_t *alloc(size_t size) {
size = align(size);
// ---------------------------------------------------------
// 1. Search for an available free block:
if (auto block = findBlock(size)) { // (1)
return block->data;
}
// ---------------------------------------------------------
// 2. If block not found in the free list, request from OS:
auto block = requestFromOS(size);
block->size = size;
block->used = true;
// Init heap.
if (heapStart == nullptr) {
heapStart = block;
}
// Chain the blocks.
if (top != nullptr) {
top->next = block;
}
top = block;
// User payload:
return block->data;
}
The actual reuse functionality is managed in (1) by the findBlock function. Let’s take a look at its implementation, starting from the first-fit algorithm.
First-fit search
The findBlock procedure should try to find a block of an appropriate size. This can be done in several ways. The first one we consider is the first-fit search.
The first-fit algorithm traverses all the blocks starting at the beginning of the heap (the heapStart which we initialized on first allocation). It returns the first found block if it fits the size, or the nullptr otherwise.
/**
* First-fit algorithm.
*
* Returns the first free block which fits the size.
*/
Block *firstFit(size_t size) {
auto block = heapStart;
while (block != nullptr) {
// O(n) search.
if (block->used || block->size < size) {
block = block->next;
continue;
}
// Found the block:
return block;
}
return nullptr;
}
/**
* Tries to find a block of a needed size.
*/
Block *findBlock(size_t size) {
return firstFit(size);
}
Here is a picture of the first-fit result:
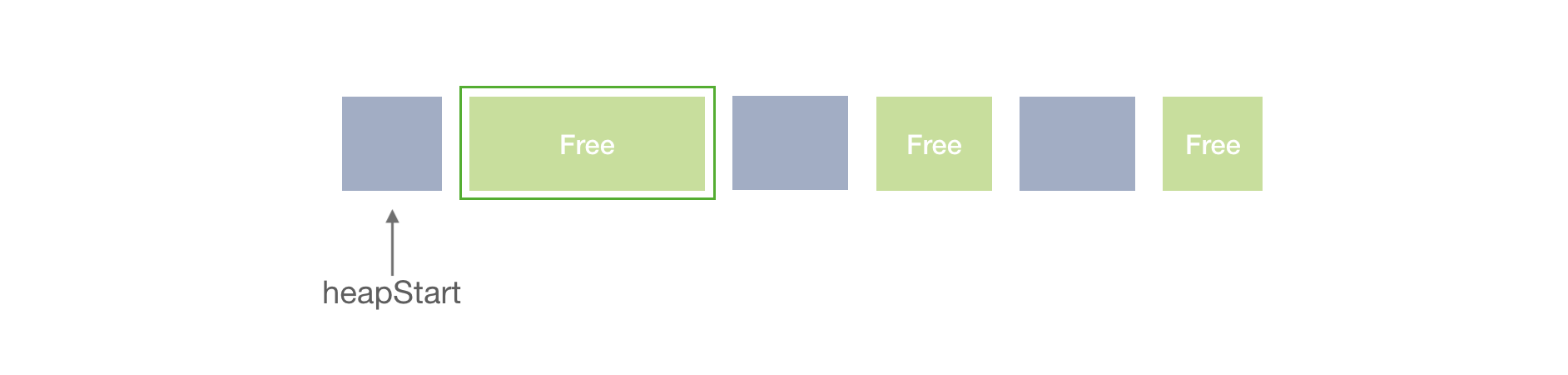
Figure 5. First-fit search
The first found block is returned, even if it’s much larger in size than requested. We’ll fix this below with the next- and best-fit allocations.
The assertion test case:
// -------------------------------------- // Test case 4: The block is reused // // A consequent allocation of the same size reuses // the previously freed block. // auto p3 = alloc(8); auto p3b = getHeader(p3); assert(p3b->size == 8); assert(p3b == p2b); // Reused!
Make sure all the assertions still pass. Now let’s see how we can improve the search of the blocks. We consider now the next-fit algorithm, which will be your first assignment.
Assignments
Below are the assignments you’ll need to implement in order to complete and improve this allocator.
Next-fit search
The next-fit is a variation of the first-fit, however it continues the next search from the previous successful position. This allows skipping blocks of a smaller size at the beginning of the heap, so you don’t have to traverse them constantly getting frequent requests for larger blocks. When it reaches the end of the list it starts over from the beginning, and so is sometimes called circular first-fit allocation.
Again the difference from the basic first-fit: say you have 100 blocks of size 8 at the beginning of the heap, which are followed by the blocks of size 16. Each alloc(16) request would result in traversing all those 100 blocks at the beginning of the heap in first-fit, while in the next-fit it’ll start from the previous successful position of a 16-size block.
Here is a picture example:

Figure 6. Next-fit search
On the subsequent request for a larger block, we find it right away, skipping all the smaller blocks at the beginning.
Let’s define the search mode, and also helper methods to reset the heap:
/**
* Mode for searching a free block.
*/
enum class SearchMode {
FirstFit,
NextFit,
};
/**
* Previously found block. Updated in `nextFit`.
*/
static Block *searchStart = heapStart;
/**
* Current search mode.
*/
static auto searchMode = SearchMode::FirstFit;
/**
* Reset the heap to the original position.
*/
void resetHeap() {
// Already reset.
if (heapStart == nullptr) {
return;
}
// Roll back to the beginning.
brk(heapStart);
heapStart = nullptr;
top = nullptr;
searchStart = nullptr;
}
/**
* Initializes the heap, and the search mode.
*/
void init(SearchMode mode) {
searchMode = mode;
resetHeap();
}
Go ahead, and implement the next-fit algorithm:
...
/**
* Next-fit algorithm.
*
* Returns the next free block which fits the size.
* Updates the `searchStart` of success.
*/
Block *nextFit(size_t size) {
// Implement here...
}
/**
* Tries to find a block that fits.
*/
Block *findBlock(size_t size) {
switch (searchMode) {
case SearchMode::FirstFit:
return firstFit(size);
case SearchMode::NextFit:
return nextFit(size);
}
}
And here is a test-case for it:
... // Init the heap, and the searching algorithm. init(SearchMode::NextFit); // -------------------------------------- // Test case 5: Next search start position // // [[8, 1], [8, 1], [8, 1]] alloc(8); alloc(8); alloc(8); // [[8, 1], [8, 1], [8, 1], [16, 1], [16, 1]] auto o1 = alloc(16); auto o2 = alloc(16); // [[8, 1], [8, 1], [8, 1], [16, 0], [16, 0]] free(o1); free(o2); // [[8, 1], [8, 1], [8, 1], [16, 1], [16, 0]] auto o3 = alloc(16); // Start position from o3: assert(searchStart == getHeader(o3)); // [[8, 1], [8, 1], [8, 1], [16, 1], [16, 1]] // ^ start here alloc(16);
OK, the next-fit might be better, however it still would return an oversized block, even if there are other blocks which fit better. Let’s take a look at the best-fit algorithm, which solves this issue.
Best-fit search
The main idea of the best-fit search, is to try finding a block which fits the best.
For example, having blocks of [4, 32, 8] sizes, and the request for alloc(8), the first- and the next-fit searches would return the second block of size 32, which unnecessary wastes the space. Obviously, returning the third block of size 8 would fit the best here.
Note: below we’re going to implement blocks splitting, and the block of size 32 from above would result in splitting it in two blocks, taking only 8 requested bytes for the first one.
Here is a picture example:

Figure 7. Best-fit search
The first free block is skipped here, being too large, so the search results in the second block.
/**
* Mode for searching a free block.
*/
enum class SearchMode {
...
BestFit,
};
...
/**
* Best-fit algorithm.
*
* Returns a free block which size fits the best.
*/
Block *bestFit(size_t size) {
// Implement here...
}
/**
* Tries to find a block that fits.
*/
Block *findBlock(size_t size) {
switch (searchMode) {
...
case SearchMode::BestFit:
return bestFit(size);
}
}
And here is a test case:
... init(SearchMode::BestFit); // -------------------------------------- // Test case 6: Best-fit search // // [[8, 1], [64, 1], [8, 1], [16, 1]] alloc(8); auto z1 = alloc(64); alloc(8); auto z2 = alloc(16); // Free the last 16 free(z2); // Free 64: free(z1); // [[8, 1], [64, 0], [8, 1], [16, 0]] // Reuse the last 16 block: auto z3 = alloc(16); assert(getHeader(z3) == getHeader(z2)); // [[8, 1], [64, 0], [8, 1], [16, 1]] // Reuse 64, splitting it to 16, and 24 (considering header) z3 = alloc(16); assert(getHeader(z3) == getHeader(z1)); // [[8, 1], [16, 1], [24, 0], [8, 1], [16, 1]]
OK, looks better! However, even with the best-fit we may end up returning a block which is larger than the requested. We should now look at another optimization, known as blocks splitting.
Blocks splitting
Currently if we found a block of a suitable size, we just use it. This might be inefficient in case if a found block is much larger than the requested one.
We shall now implement a procedure of splitting a larger free block, taking from it only a smaller chunk, which is requested. The other part stays free, and can be used in further allocation requests.
Here is an example:
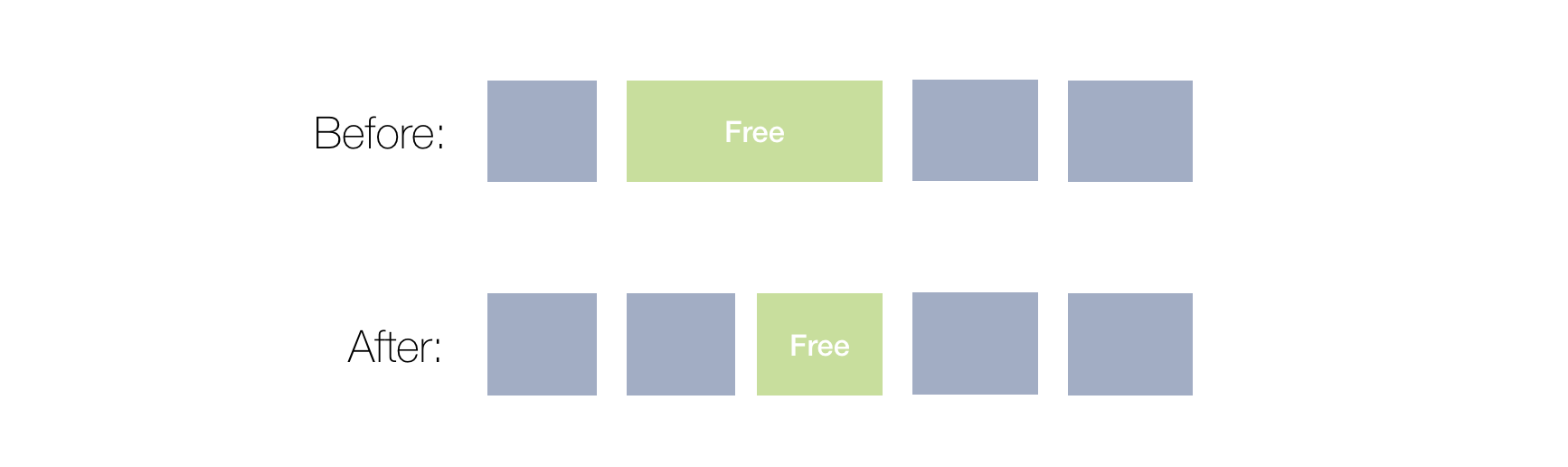
Figure 8. Block split
Our previous first-fit algorithm would just took the whole large block, and we would be out of free blocks in the list. With the blocks splitting though, we still have a free block to reuse.
The listAllocate function is called whenever a block is found in the searching algorithm. It takes care of splitting a larger block on smaller:
/**
* Splits the block on two, returns the pointer to the smaller sub-block.
*/
Block *split(Block *block, size_t size) {
// Implement here...
}
/**
* Whether this block can be split.
*/
inline bool canSplit(Block *block, size_t size) {
// Implement here...
}
/**
* Allocates a block from the list, splitting if needed.
*/
Block *listAllocate(Block *block, size_t size) {
// Split the larger block, reusing the free part.
if (canSplit(block, size)) {
block = split(block, size);
}
block->used = true;
block->size = size;
return block;
}
With splitting we have now good reuse of the free space. Yet however, if we have two fee adjacent blocks on the heap of size 8, and a user requests a block of size 16, we can’t satisfy an allocation request. Let’s take a look at another optimization for this — the blocks coalescing.
Blocks coalescing
On freeing the objects, we can do the opposite to splitting operation, and coalesce two (or more) adjacent blocks to a larger one.
Here is an example:
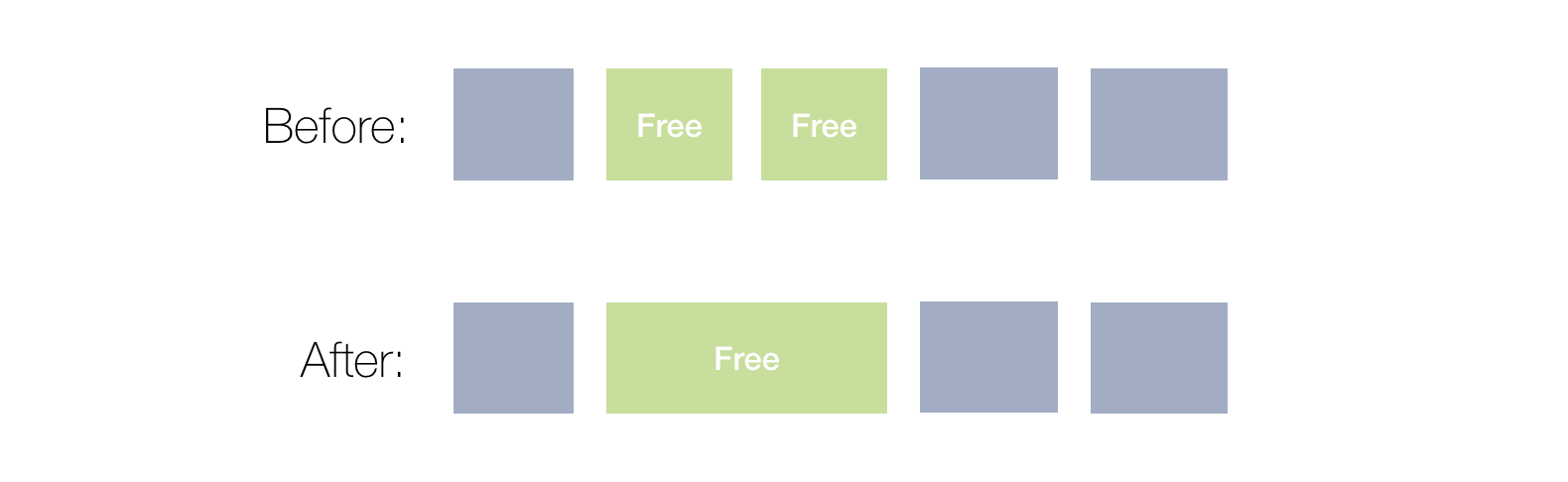
Figure 9. Blocks coalescing
Go ahead and implement the merging procedure:
...
/**
* Whether we should merge this block.
*/
bool canCoalesce(Block *block) {
return block->next && !block->next->used;
}
/**
* Coalesces two adjacent blocks.
*/
Block *coalesce(Block *block) {
// Implement here...
}
/**
* Frees the previously allocated block.
*/
void free(word_t *data) {
auto block = getHeader(data);
if (canCoalesce(block)) {
block = coalesce(block);
}
block->used = false;
}
Notice that we coalesce only with the next block, since we only have access to the next pointer. Experiment with adding prev pointer to the object header, and consider coalescing with the previous block as well.
Blocks coalescing allows us satisfying allocation requires for larger blocks, however, we still have to traverse the list with O(n) approach in order to find a free block. Let’s see how we can fix this with the explicit free-list algorithm.
Explicit Free-list
Currently we do a linear search analyzing each block, one by one. A more efficient algorithm would be using an explicit free-list, which links only free blocks.
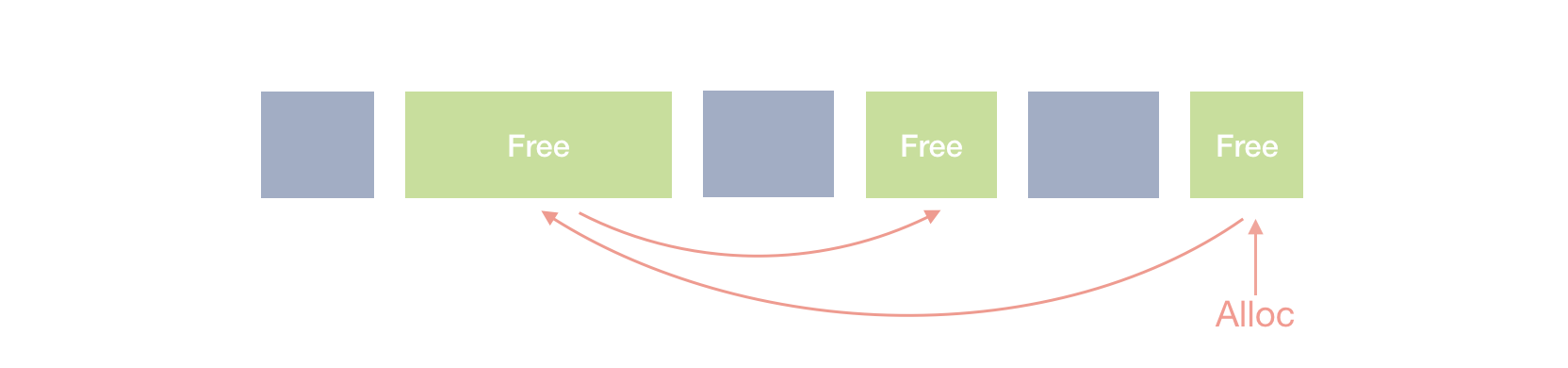
Figure 10. Explicit Free-list
This might be a significant performance improvement, when the heap is getting larger, and one needs to traverse a lot of objects in the basic algorithms.
An explicit free-list can be implemented directly in the object header. For this the next, and prev pointers would point to the free blocks. Procedures of splitting and coalescing should be updated accordingly, since next, and prev won’t be pointing to adjacent blocks anymore.
Alternatively, one could just have a separate additional free_list data structure (std::list would work):
#include <list> /** * Free list structure. Blocks are added to the free list * on the `free` operation. Consequent allocations of the * appropriate size reuse the free blocks. */ static std::list<Block *> free_list;
The alloc procedure would just traverse the free_list: if nothing is found, request from OS:
/**
* Mode for searching a free block.
*/
enum class SearchMode {
...
FreeList,
};
/**
* Explicit free-list algorithm.
*/
Block *freeList(size_t size) {
for (const auto &block : free_list) {
if (block->size < size) {
continue;
}
free_list.remove(block);
return listAllocate(block, size);
}
return nullptr;
}
/**
* Tries to find a block that fits.
*/
Block *findBlock(size_t size) {
switch (searchMode) {
...
case SearchMode::FreeList:
return freeList(size);
}
}
The free operation would just put the block into the free_list:
/**
* Frees the previously allocated block.
*/
void free(word_t *data) {
...
if (searchMode == SearchMode::FreeList) {
free_list.push_back(block);
}
}
Experiment and implement a doubly-linked list approach, using next, and prev in the header for the free-list purposes.
Finally let’s consider one more speed optimization, which brings much faster search for blocks of predefined sizes. The approach is knows as segregated list.
Segregated-list search
Considered above searching algorithms (first-fit, next-fit, and the best-fit) do a linear search through the blocks of different sizes. This slows down the search of a block of an appropriate size. The idea of the segregated-fit is to group the blocks by size.
That is, instead of one list of blocks, we have many lists of blocks, but each list contains only blocks of a certain size.
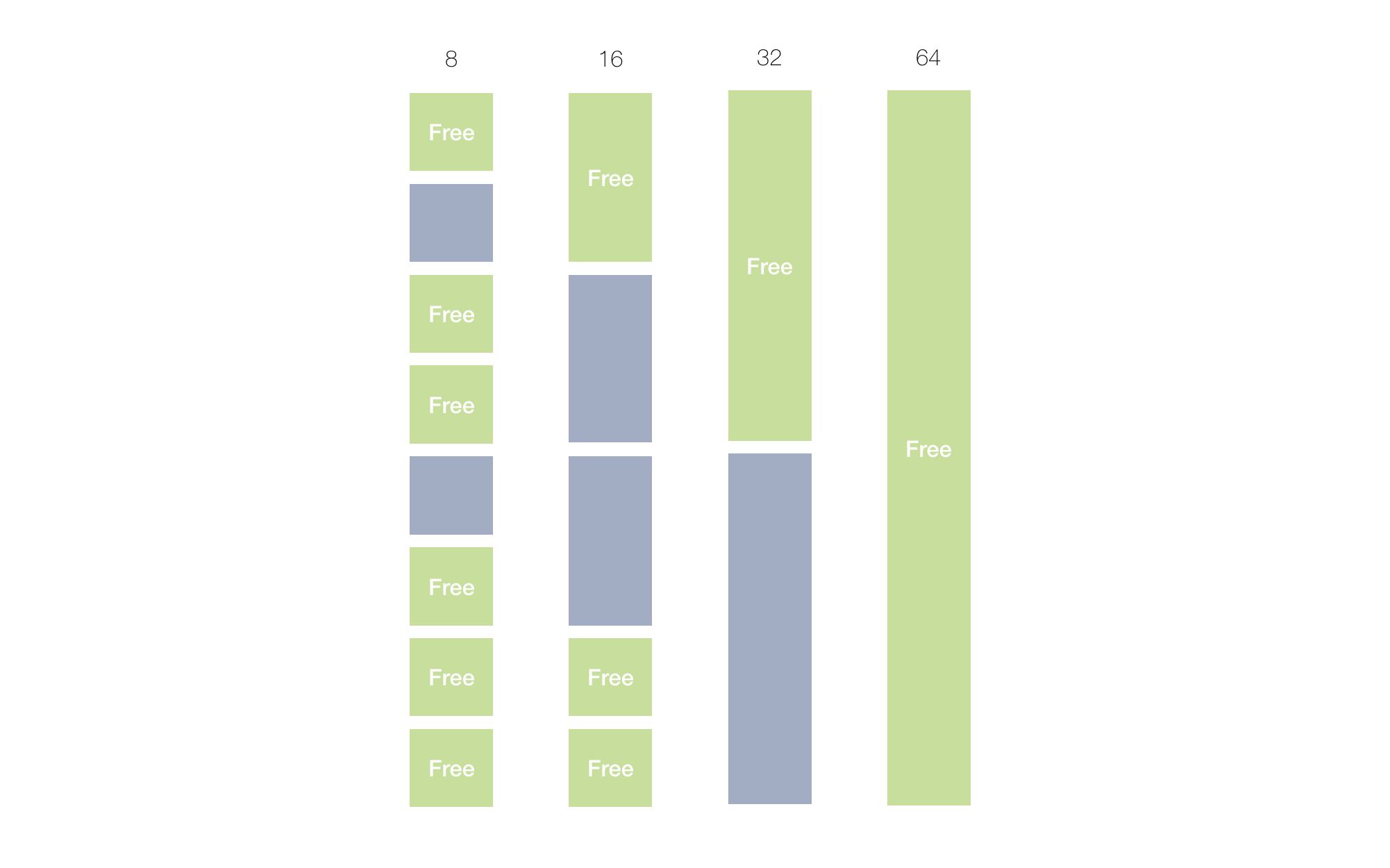
Figure 11. Segregated list
In this example the first group contains blocks only of size 8, the second group — of size 16, third — 32, etc. Then, if we get a request to allocate 16 bytes, we directly jump to the needed bucket (group), and allocate from there.
There are several implementations of the heap segregation. One can pre-allocate a large arena, and split it on buckets, having a contiguous array of buckets, with fast jumps to needed group and a block within a group.
Another approach is to have just an array of lists. Example below initializes these segregated lists. When a first block of the appropriate size is allocated, it replaces the nullptr value in the bucket. Next allocation of the same size chains it further.
That is, instead of one heapStart, and top, we have many “heapStarts”, and “tops”
/**
* Segregated lists. Reserve the space
* with nullptr. Each list is initialized
* on first allocation.
*/
Block *segregatedLists[] = {
nullptr, // 8
nullptr, // 16
nullptr, // 32
nullptr, // 64
nullptr, // 128
nullptr, // any > 128
};
And the actual search within a bucket can reuse any of the considered above algorithms. In the example below we reuse firstFit search.
enum class SearchMode {
...
SegregatedList,
};
...
/**
* Gets the bucket number from segregatedLists
* based on the size.
*/
inline int getBucket(size_t size) {
return size / sizeof(word_t) - 1;
}
/**
* Segregated fit algorithm.
*/
Block *segregatedFit(size_t size) {
// Bucket number based on size.
auto bucket = getBucket(size);
auto originalHeapStart = heapStart;
// Init the search.
heapStart = segregatedLists[bucket];
// Use first-fit here, but can be any:
auto block = firstFit(size);
heapStart = originalHeapStart;
return block;
}
/**
* Tries to find a block that fits.
*/
Block *findBlock(size_t size) {
switch (searchMode) {
...
case SearchMode::SegregatedList:
return segregatedFit(size);
}
}
OK, we have optimized the search speed. Now let’s see how we can optimize the storage size.
Optimizing the storage
Currently object header is pretty heavy: it contains size, used, and next fields. One can encode some of the information more efficiently.
For example, instead of explicit next pointer, we can get access to the next block by simple size calculation of the block.
In addition, since our blocks are aligned by the word size, we can reuse LSB (least-significant bits) of the size field for our purposes. For example: 1000 — size 8, and is not used. And the 1001 — size 8, and is used.
The header structure would look as follows:
struct Block {
// -------------------------------------
// 1. Object header
/**
* Object header. Encodes size and used flag.
*/
size_t header;
// -------------------------------------
// 2. User data
/**
* Payload pointer.
*/
word_t data[1];
};
And couple of encoding/decoding functions:
/**
* Returns actual size.
*/
inline size_t getSize(Block *block) {
return block->header & ~1L;
}
/**
* Whether the block is used.
*/
inline bool isUsed(Block *block) {
return block->header & 1;
}
/**
* Sets the used flag.
*/
inline void setUsed(Block *block, bool used) {
if (used) {
block->header |= 1;
} else {
block->header &= ~1;
}
}
This is basically trading storage for speed. In case when you have a smaller storage, you may consider such encoding/decoding. And vice-versa, when you have a lot of storage, and the speed matters, using explicit fields in structure might be faster, than constant encoding and decoding of the object header data.
Custom sbrk
As was mentioned above, on Mac OS sbrk is currently deprecated and is emulated via mmap.
(Wait, so if sbrk is deprecated, why did we use it?)
What is deprecated is the specific function, and on specific OS. However by itself, the sbrk is not just a “function”, it’s the mechanism, an abstraction. As mentioned, it also directly corresponds to the bump-allocator.
Production malloc implementations also use mmap instead of brk, when a larger chunk of memory is requested. In general mmap can be used for both, mapping of external files to memory, and also for creating anonymous mappings (not backed by any file). The later is exactly used for memory allocation.
Example:
#include <sys/mman.h>
...
/**
* Allocation arena for custom sbrk example.
*/
static void *arena = nullptr;
/**
* Program break;
*/
static char *_brk = nullptr;
/**
* Arena size.
*/
static size_t arenaSize = 4194304; // 4 MB
...
// Map a large chunk of anonymous memory, which is a
// virtual heap for custom sbrk manipulation.
arena = mmap(0, arenaSize, PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
Instead of using the standard sbrk, implement own one:
void *_sbrk(intptr_t increment) {
// Implement here...
// 0. Pre-allocate a large arena using `mmap`. Init program break
// to the beginning of this arena.
// 1. If `increment` is 0, return current break position.
// 2. If `current + increment` exceeds the top of
// the arena, return -1.
// 3. Otherwise, increase the program break on
// `increment` bytes.
}
Conclusion
At this point we’re finishing our discussion about memory allocators, and in the next lectures will be working already with garbage collection algorithms. As we will see, different collectors work with different allocators, and designing a memory manager requires choosing a correct correspondence between the collector, and allocator.
Again, you can enroll to full course here:
Try solving all the assignments yourself first. If you’re stuck, you can address the full source code with the solutions here.
To summarize our lecture:
- Sequential (Bump) allocator is the fastest, and is similar to the stack allocation: just continuously bump the allocation pointer. Unfortunately, not every programming language can allow usage of the Bump-allocator. In particular, C/C++, which expose the pointers semantics, cannot relocate objects on GC cycle, and therefore has to use slower Free-list allocator
- Bump-allocator is used in systems with Mark-Compact, Copying, and Generational collectors
- Free-list allocator is slower, and traverses the linked list of blocks, until it finds a block of a needed size. This traversal is the main reason why the heap allocation is in general considered slower than the stack allocation (which is not true in case of the Bump-allocator)
- Free-list allocator (such as
malloc) is used in systems with Mark-Sweep, Reference counting collectors, and also in systems with manual memory management - List search can be implemented as first-fit, next-fit, and best-fit algorithms
- Even faster list search can be achieved by using an explicit free-list
- And even more faster search can be achieved in the segregated free-lists
- Encoding object header, consider trading speed for storage, and vice-versa
If you have any questions, or suggestions, as always I’ll be glad to discuss them in comments. And see you in the class!
Written by: Dmitry Soshnikov
Published on: Feb 6th, 2019
Thanks for your work, great explanation. I’m wondering if the object header is always located together with the data block?
@Alex Levine, thanks for the feedback, glad you liked it.
This is purely implementation-dependent. Co-locating the header with the user data is the usual approach (see this example). However, other
mallocimplementation can store it in different location.thank you, sir, crystal clear!
one question: in custom
sbrk, whenmmaparena is exhausted, what happens?@saurabh nair, thanks, glad it’s useful. As for arena, once it’s exhausted, and collector didn’t reclaim anything, you can simply extend the arena, or allocate another one, and chain them.
Thank you for the lecture! I love your classes.
Ive’ a question. How does garbage collector distinguishes pointers from numbers?
@Jeremy Chen, thanks for the feedback!
That’s a good question, and this depends on the implementation.
For example, conservative collectors (such as Mark-Sweep for C++) treats any number which looks like a pointer as a potential pointer (such number should be address-aligned, and be in the range-addresses of the heap), and tries to reach it.
Other systems can use addition encoding for data, and distinguish directly numbers from pointers.
Hi, thank you for your lectures. They are self-contained and really well explained.
I had a couple questions:
1. When are the remaining lectures coming out? Any estimated time?
2. What do you use to make your slides? They look beautiful!
@Hari, thanks for the feedback, glad it’s useful. I teach these classes offline, and need to convert them to video format. The other lectures are coming soon, including for other classes as well (stay tuned!). As for the slides, I use combination of tools: Good Notes/Notability, Keynote, After Effects, live drawing and editing, etc.
The test for the Best-Fit search is incorrect. It verifies the algorithm’s functionality but not it’s correctness. To do that you’d need to have at least 2 blocks of memory with the the first one (and possibly others) being not “best-fit”. A trivial example would be:
@Anonymous: good point. I have updated the test case for the Best-fit search to (can be found here as well):
Also notice, you can’t split block of size 32 to two blocks of 16, since you need to take into account the size of the object headers. So I used block of size 64 for splitting use case.
Thanks for great function for align, I used it in my project
Thank you for the material, it is great. I have one question though: how to utilize shared memory? As I recall, you cant use pointers in it – are there any other algorithms that apply? At the end, I would like to use shared memory as STL custom memory allocator for small objects, like map.
Thank you in advance!
@Nikola Radovanovic, thanks for the feedback, glad it’s useful.
As for shared memory allocation and IPC, yes, it’s a different story, and casual pointers are useless there, since another process will have memory mapped to different regions. In this case you’ll have to use offsets (as “virtual pointers”) within the allocated shared block. You can take a look at this paper as an example.
@Dmitry Soshnikov
Thank you very much: I suspected offset will come into play but wanted to be assured by an expert. I would like to use some allocating algorithm in order to lower the fragmentation – to return freed objects back into the pool since that way I can maybe develop small in-memory DB which will hold list of say processes with arguments that needs to be (re)started and health checked.
Best regards
@Nikola Radovanovic, yes, a pool-allocator might actually be a better option here (especially with shared memory). You can take a look at this article as an example. It allocates in non-shared memory and with using pointers, however the approach can be migrated to the offsets in a shared block. Good luck with the in-memory DB!
Thank you! Bought the course on Udemy – all of my wet dreams become reality 🙂
Instructional article 🙂
Blocks. They are not freed when Allocator goes out of scope. I assume this is a deliberate mem-leak to be clarified and solved in the class? Perhaps it would be nice to mention for the readers who will not attend the class…
I assume you might not solve it with ` std::vector blocks{0};`. What would you use? Simple C like linked list of some `struct Block{}` ?
Please advise …
@dbjdbj, good point, and yes, in this case the allocator should stay in-scope (that is, to be a global allocator throughout the program lifecycle). Alternatively, if you maintain an allocator instance (e.g. per-thread), you’ll need to deallocate the blocks in the destructor — by just going through the list, and calling `delete` on each allocated block.
Wonderful article Dmitry! Really insightful. Thank you for sharing 🙂
@Karki, thanks for the feedback, and glad it’s useful!
Hi Dimitry, thanks for the article!
Came here while searching for a simple allocator for a wchar_t*.
This I guess, comes out as a “C-style” approach, and thus not very much in the spirit of your article. In fact there are many who find the use of the alloc functions this way altogether unattractive.
For my purposes, the requirements are small in that the variable is used in a Listview subclass as the LV title, and the following arrangement for that is hoped to be something along these lines:
Class MyVar() { wchar_t *myVar; const int allocsize = 100; GetMyVar() { if (myVar) return myVar else return (wchar_t *)calloc(allocSize, SIZEOF_WCHAR); } ReleaseMyVar() { if (myVar) Free(myVar) } }So long as the variable is released at program termination, does that ring true to you?
Thanks.
Thanks for the article.
You mention using std::list for implementation of the Explicit Free-List. Wouldn’t using a separate data structure that requires dynamic memory defeat the purpose of writing a custom allocator? Presumably as the list grows, memory will need to be allocated which would result in the slower calls to malloc/new, right?
I’m not sure using a separate data structure is ever an option, if the intent is to avoid using malloc/new.
@Laurie Stearn — if you need to lazily allocate the title, this seems reasonable. Although since you keep a raw pointer in
myVar, it’s good to have a destructor, so it correctly deallocates the memory. Also notice, since it’s an unowned raw pointer, this may break if the data is allocated somewhere on the stack and is gone.@Adam St. Amand — yes, the
std::listis used mainly as an explanatory example. Depending on your implementation, you will likely have a custom list structure to keep free nodes.However if you implement some VM which has an allocated sandbox heap, your actual implementation may keep any needed data structures to maintain that sandbox heap.
I find it impossible to follow C++ examples without proper C++ knowledge. Stating that “you can allocate a virtual heap in JavaScript using ArrayBuffer, or similarly bytearray in Python, Rust, etc.” does not help much because further ahead you must reimplement the algorithms in your “target” language and without clear understanding of what’s going on there is hardly any way to proceed.
Besides, sbrk might not be available for your language of choice or best case one has to dig docs in order to find either an alternative or some wrapper which does not exactly do the same thing. The course does not explicitly state that C++ is a requirement when it clearly IS a requirement. This is dishonest towards people who purchase it.
@tastyminerals, thanks for the feedback. Yes, this article on memory allocators is specific to C++. The Garbage Collection Algorithms course though is mainly focused around GC itself rather than on memory allocators, and is represented in the view of abstract algorithms (in pseudo-code), not tight to specific languages.
Allocating a byte array (or any array of objects) in a higher-level programming languages, and maintaining the break pointer as a simple variable (for implementing
sbrk) should be doable for an intermediate level engineer who this course is targeted on.Garbage Collection Algorithms are not about “bytes” specifically. They describe abstract concepts how to automatically reclaim objects which aren’t used. Those objects might be rows in a database, instances in a list, etc.
“brk(heapStart);” is not defined in Next-fit section.
@tastyminerals,
This article contains only high-level code pointers for implementing a memory allocator. You may take a look at the full source code for this article, here.
In particular, the
heapStartvariable is defined here:And the
brkis the standard *nix function for manipulating the program break.Calling the
brk(heapStart)just sets the position of the program break to the heap start.Here is example how to implement it in a higher-level language, e.g. in JavaScript.
Shouldn’t we set the
block.used = truein fit algorithms? Because in “firstFit” implementation it is not set and I wrote the subsequent “nextFit” and “bestFit” accordingly but when debugging “bestFit” tests you can clearly see thatfreed z2, z1 allocate me block of 16 reuse from [564CD4988000, 564CD4988028, 564CD49880C0, 564CD49880E8] 564CD4988000 block does not fit because used = true, its size is 8 but requested 16, skipping 564CD4988028 block does not fit because used = false, its size is 64 but requested 16, skipping 564CD49880C0 block does not fit because used = true, its size is 8 but requested 16, skipping found block 564CD49880E8 is it used? = false and its size = 16 reusing z3 (16 bytes) at 564CD49880E8 [564CD4988000, 564CD4988028, 564CD49880C0, 564CD49880E8] allocate me block of 16 reuse from [564CD4988000, 564CD4988028, 564CD49880C0, 564CD49880E8] 564CD4988000 block does not fit because used = true or its size is 8 but requested 16, skipping 564CD4988028 block does not fit because used = false or its size is 64 but requested 16, skipping 564CD49880C0 block does not fit because used = true or its size is 8 but requested 16, skipping found block 564CD49880E8 is it used? = false and its size = 16 reusing z4 (16 bytes) at 564CD49880E8 // again? but it is already in use by z3So, basically when the “bestFit” test does
z4reusesz3address which should be already used by that time by z3. But sinceblock.usedis only set inallocafterfindBlockreturns, you canalloc(16)as much as you want and it will always use the same address. Is my understanding correct?@tastyminerals, yes, the
usedis also set inlistAllocate, which is called from the “fit” algorithms.After coalescing current block with the next block, shouldn’t we remove the entry of the next block from the free_list before pushing the coalesced one?
While resetting heap in the function resetHeap(), since we are not releasing the previously claimed memory back to kernel and changing heapStart and other variables to null, won’t there be a memory leak?
@Satyam Sharma – thanks for the feedback, yes, this article gives a basic idea, which you can further extend to your needs, including more granular handling of the allocated blocks.
Thanks for this detailed tutorial.
A small question on block splitting. I think the comment on the following test case is wrong:
“`
// [[8, 1], [64, 0], [8, 1], [16, 1]]
// Reuse 64, splitting it to 16, and 48
z3 = alloc(16);
assert(getHeader(z3) == getHeader(z1));
// [[8, 1], [16, 1], [48, 0], [8, 1], [16, 1]]
“`
When taking the splitted-out header into account, the latter block’s size should be 24 (with another 24 being the size of the header on `x86_64`), not 48, and you already mentioned that on 2019-09-08, but did not correct it.
Also, the following line in the `split` function in your source code
“`
freePart->size = block->size – size;
“`
should be changed to
“`
freePart->size = block->size – allocSize(size);
“`
if I did not take it wrong.
@Yuquan Chi, yes, this should be 24, I updated the source code – thanks for catching it!